Chapter 11 Web data, Twitter
This unit spans Mon Apr 13 through Sat Apr 18.
At 11:59 PM on Sat Apr 18 the following items are due:
- DC 22 - Importing from the web: 1
- DC 23 - Importing from the web: 2
We are going to cover quite a bit of ground in this unit. We start by working with JSON, which is a widespread data format for web data. Then we work with the Twitter API via the twitteR package and do a brief sentiment analysis comparing Maine and Vermont. Your results will look different than mine because you’ll be capturing live data from Twitter during a different time frame.
11.1 Media
Reading: Getting started with jsonlite (vignette)
Reading: Getting started with plyr (vignette)
Video: Accessors in R
Video: Importing JSON in R
11.2 JSON
JavaScript Object Notation (JSON) is a data interchange format that is lightweight and commonly used for representing and sharing data in web applications. There are two basic structures in JSON:
- name:value pairs
- ordered lists of values
We’ll look at some elements from a JSON file we’ll be working with later in this unit - Veterans’ Service Offices from maine.gov. This file is currently not accessible on the Maine Government website.
, {
"id" : 255600352,
"name" : "Contact",
"dataTypeName" : "text",
"fieldName" : "contact",
"position" : 2,
"renderTypeName" : "text",
"tableColumnId" : 34195245,
"width" : 184,
"cachedContents" : {
"non_null" : 8,
"largest" : "Matthew Haley",
"null" : 0,
"top" : [ {
"item" : "Don Dare",
"count" : 20
}, {
"item" : "Christopher Haskell",
"count" : 19
}, {
"item" : "Jerry Smith",
"count" : 18
}, {
"item" : "Lynette Ramsey",
"count" : 17
}, {
"item" : "Matthew Haley",
"count" : 16
}, {
"item" : "David Flores",
"count" : 15
}, {
"item" : "John Norton",
"count" : 14
}, {
"item" : "Conrad Edwards",
"count" : 13
} ],
"smallest" : "Christopher Haskell"
},A couple of quick syntax notes:
- curly braces
{}are called containers - square brackets
[]contain arrays - the colon
:separates the names and values
A lot of the elements we see appear nonsensical or redundant. In some cases they were just generated by the application creating the JSON file - for example, it seems largest : and smallest : refer to the alphanumeric ordering by the contact name that appears in item :. Some of the data is used for rendering purposes, and we aren’t interested in that either. For our purposes, here are the interesting portions of the snippet of the JSON file above.
"name" : "Contact"is metadata that tells us what this container contains - contacts."dataTypeName" : "text""item" :contains the name of the contact
These element names are created by whoever (person) or whatever (application) created the JSON file. Sometimes there is further information provided in other portions of the document, but for this example, we have no concept of what "count" : might be all about. When we look at the entire JSON file, we can see the data we want is in the "data: " elements near the bottom (line 493), the "name": element in the columns containers starting on line 29 (note: columns is nested inside the view container which is nested inside the meta container). I’m also loading all the libraries I’ll need for the JSON sections of this unit.
11.3 jsonlite
If you open the JSON file in RStudio or a text editor, you’ll realize the actual data is in the data: section we mentioned earlier near the end of the file, starting at line 493. We can extract that data node from the raw file variable, but because there are nested elements, the data is not simplified into a data frame – it is a list of lists. The outer list contains eight lists - one for each VA office. The inner lists contain fifteen elements of data, some of which have multiple values, which can still be complex. For example, if I return the 12th element of the first list with va[[1]][[12]] (below), I see it returns a list of five elements. The first element is the address container, but I have no idea what the remaining four values represent as three of them are NA and one is TRUE.
## [1] "{\"address\":\"248 Room\",\"city\":\"Togus\",\"state\":\"ME\",\"zip\":\"04330\"}"
## [2] NA
## [3] NA
## [4] NA
## [5] "TRUE"## [1] "sid" "id" "position" "created_at" "created_meta"
## [6] "updated_at" "updated_meta" "meta" "Name" "Contact"
## [11] "Town" "Location" "Phone" "Fax" "Email"Looking at the column names, I realize I only want the data from sublists 9-15. I’m going to take a peek at the first record for these six lists to see the structure of the data in those six lists.
## [[1]]
## [1] "Togus Bureau of Veterans' Services Office"
##
## [[2]]
## [1] "John Norton"
##
## [[3]]
## [1] "Togus"
##
## [[4]]
## [1] "{\"address\":\"248 Room\",\"city\":\"Togus\",\"state\":\"ME\",\"zip\":\"04330\"}"
## [2] NA
## [3] NA
## [4] NA
## [5] "TRUE"
##
## [[5]]
## [1] "207-623-8411, ext. 5228\nor 207-623-5732"
##
## [[6]]
## [1] "207-287-8449"
##
## [[7]]
## [1] "mailvsome@va.gov"It looks like the address info is my only multiple element list, and I’m semi-comfortable assuming that I only want the first element in that list but to verify, since there are only eight VA offices, I’ll look at all eight lists:
## [[1]]
## [[1]][[1]]
## [1] "{\"address\":\"248 Room\",\"city\":\"Togus\",\"state\":\"ME\",\"zip\":\"04330\"}"
## [2] NA
## [3] NA
## [4] NA
## [5] "TRUE"
##
##
## [[2]]
## [[2]][[1]]
## [1] "{\"address\":\"35 Westminster Street\",\"city\":\"Lewiston\",\"state\":\"ME\",\"zip\":\"04240\"}"
## [2] "44.07552"
## [3] "-70.175044"
## [4] NA
## [5] "FALSE"
##
##
## [[3]]
## [[3]][[1]]
## [1] "{\"address\":\"7 Court Street\",\"city\":\"Machias\",\"state\":\"ME\",\"zip\":\"04654\"}"
## [2] "44.718235"
## [3] "-67.453171"
## [4] NA
## [5] "FALSE"
##
##
## [[4]]
## [[4]][[1]]
## [1] "{\"address\":\"35 State Hospital Drive\",\"city\":\"Bangor\",\"state\":\"ME\",\"zip\":\"04401\"}"
## [2] "44.813337"
## [3] "-68.741164"
## [4] NA
## [5] "FALSE"
##
##
## [[5]]
## [[5]][[1]]
## [1] "{\"address\":\"74 Drummond Avenue\",\"city\":\"Waterville\",\"state\":\"ME\",\"zip\":\"04901\"}"
## [2] "44.569695"
## [3] "-69.627807"
## [4] NA
## [5] "FALSE"
##
##
## [[6]]
## [[6]][[1]]
## [1] "{\"address\":\"628 Main Street\",\"city\":\"Springvale\",\"state\":\"ME\",\"zip\":\"04083\"}"
## [2] "43.455161"
## [3] "-70.789839"
## [4] NA
## [5] "FALSE"
##
##
## [[7]]
## [[7]][[1]]
## [1] "{\"address\":\"151 Jetport Boulevard\",\"city\":\"Portland\",\"state\":\"ME\",\"zip\":\"04102\"}"
## [2] "43.648818"
## [3] "-70.315417"
## [4] NA
## [5] "FALSE"
##
##
## [[8]]
## [[8]][[1]]
## [1] "{\"address\":\"456 York Street\",\"city\":\"Caribou\",\"state\":\"ME\",\"zip\":\"04736\"}"
## [2] "46.851041"
## [3] "-68.043075"
## [4] NA
## [5] "FALSE"It appears as though two of the elements that were NA in the first list are missing values for lon and lat. Also, I’m using the plyr function llply. While much of the plyr functions working with data frames are implemented in dplyr, the functions working with lists are still valuable. We don’t spend enough time in this course working with lists to warrant allocating significant time to list manipulation.
We’ll convert everything we want except the location data to a data frame first. In other words, sublists 9-11, 13-15. Even though data frames and lists are similar objects, converting a list of lists to a data frame takes multiple steps and can be done in numerous ways. I’ll use the most straightforward way.
- Subset the large list of lists to a smaller list of lists with the necessary data using plyr::laply - which splits lists, applies a function, then returns lists.
- Treat each list as an observation(row) and row bind each list to a data frame.
First a quick description of the list problem we have. The simple lists of the data we want are sublists 9-11 and 13-15. Referencing a list element inside a specific list of lists is fairly straightforward. The example below shows sublist 9 from list 1 which shows the name of the Veteran’s Service Office from list 1:
## [[1]]
## [1] "Togus Bureau of Veterans' Services Office"If we want to reference all of the sublist 9’s the code isn’t as straightforward as we would hope. We’ll use plyr::llply to apply a function to a list
## [[1]]
## [[1]][[1]]
## [1] "Togus Bureau of Veterans' Services Office"
##
##
## [[2]]
## [[2]][[1]]
## [1] "Lewiston Bureau of Veterans' Services Office"
##
##
## [[3]]
## [[3]][[1]]
## [1] "Machias Bureau of Veterans' Services Office"
##
##
## [[4]]
## [[4]][[1]]
## [1] "Bangor Bureau of Veterans' Services Office"
##
##
## [[5]]
## [[5]][[1]]
## [1] "Waterville Bureau of Veterans' Services Office"
##
##
## [[6]]
## [[6]][[1]]
## [1] "Springvale Bureau of Veterans' Services Office"
##
##
## [[7]]
## [[7]][[1]]
## [1] "South Portland Bureau of Veterans' Services Office"
##
##
## [[8]]
## [[8]][[1]]
## [1] "Caribou Bureau of Veterans' Services Office"What llply does, in this case, is iterates through each list in the list an applies the function l, which references element 9 in that sublist. It is similar to typing va[[1]][9], va[[2]][9], ..., va[[8]][9]
We could also iterate the list using a for loop but llply is easier to read. We’ll use the backtick bracket function shorthand in the example below to create a list of lists of the desired lists.
va_list_data <- llply(va, `[`, c(9:11, 13:15))
# above line is the equivalent to - va_data2 <- llply(va, function(l) l[c(9:11, 13:15)])Next we use the base function do.call() to call rbind.data.frame on each list in va_data. rbind row binds each list as an observation with six columns to a data frame. We then use the column names we extracted earlier to name our columns in the data frame.
va_df <- do.call(rbind.data.frame, va_list_data)
colnames(va_df) <- column_names[c(9:11, 13:15)]
head(va_df)## Name Contact Town
## 2 Togus Bureau of Veterans' Services Office John Norton Togus
## 21 Lewiston Bureau of Veterans' Services Office Jerry Smith Lewiston
## 3 Machias Bureau of Veterans' Services Office Lynette Ramsey Machias
## 4 Bangor Bureau of Veterans' Services Office Don Dare Bangor
## 5 Waterville Bureau of Veterans' Services Office Conrad Edwards Waterville
## 6 Springvale Bureau of Veterans' Services Office David Flores Springvale
## Phone Fax
## 2 207-623-8411, ext. 5228\nor 207-623-5732 207-287-8449
## 21 207-783-5306 207-783-5307
## 3 207-255-3306 207-255-4815
## 4 207-941-3005 207-941-3012
## 5 207-872-7846 207-872-7858
## 6 207-324-1839 207-324-2763
## Email
## 2 mailvsome@va.gov
## 21 Lewiston.MaineBVS@maine.gov
## 3 Machias.MaineBVS@maine.gov
## 4 Bangor.MaineBVS@maine.gov
## 5 Waterville.MaineBVS@maine.gov
## 6 Springvale.MaineBVS@maine.govThe location is a little more challenging to deal with in that:
- the location sublist (i.e., element 12) is a list containing five character vectors.
- the first character vector is a JSON container
- two other character vectors include lat and lon
- we don’t know the meaning of the data in the remaining two character vectors
Since each list contains five character vectors with a consistent order (e.g., the first vector is address, second is lat, etc.) we can unlist the list of lists using the unlist() function. This will create a 8 * 5 = 40 element character vector. We can then format that vector as a matrix with 8 rows (observations) and 5 columns (variables) using matrix() and coerce it into a data frame with as.data.frame().
va_location <- as.data.frame(matrix(unlist(laply(va, `[`, 12)), nrow = 8, byrow = TRUE), stringsAsFactors = FALSE)
head(va_location)## V1
## 1 {"address":"248 Room","city":"Togus","state":"ME","zip":"04330"}
## 2 {"address":"35 Westminster Street","city":"Lewiston","state":"ME","zip":"04240"}
## 3 {"address":"7 Court Street","city":"Machias","state":"ME","zip":"04654"}
## 4 {"address":"35 State Hospital Drive","city":"Bangor","state":"ME","zip":"04401"}
## 5 {"address":"74 Drummond Avenue","city":"Waterville","state":"ME","zip":"04901"}
## 6 {"address":"628 Main Street","city":"Springvale","state":"ME","zip":"04083"}
## V2 V3 V4 V5
## 1 <NA> <NA> <NA> TRUE
## 2 44.07552 -70.175044 <NA> FALSE
## 3 44.718235 -67.453171 <NA> FALSE
## 4 44.813337 -68.741164 <NA> FALSE
## 5 44.569695 -69.627807 <NA> FALSE
## 6 43.455161 -70.789839 <NA> FALSEThe following five columns exist in our va_location data frame:
V1- the address in json formatV2- the latitudeV3- the longitudeV4andV5- no clue – we’ll delete these.
Since the address is JSON formatted, we can use jsonlite’s handy stream_in(textConnection()) functions to quickly separate the data. Because the data is not nested, it will simplify to a data frame with a column for each name from the name : value pair.
##
Found 8 records...
Imported 8 records. Simplifying...## address city state zip
## 1 248 Room Togus ME 04330
## 2 35 Westminster Street Lewiston ME 04240
## 3 7 Court Street Machias ME 04654
## 4 35 State Hospital Drive Bangor ME 04401
## 5 74 Drummond Avenue Waterville ME 04901
## 6 628 Main Street Springvale ME 04083We can now append the new data to our va_df data frame:
## Name Contact Town
## 2 Togus Bureau of Veterans' Services Office John Norton Togus
## 21 Lewiston Bureau of Veterans' Services Office Jerry Smith Lewiston
## 3 Machias Bureau of Veterans' Services Office Lynette Ramsey Machias
## 4 Bangor Bureau of Veterans' Services Office Don Dare Bangor
## 5 Waterville Bureau of Veterans' Services Office Conrad Edwards Waterville
## 6 Springvale Bureau of Veterans' Services Office David Flores Springvale
## Phone Fax
## 2 207-623-8411, ext. 5228\nor 207-623-5732 207-287-8449
## 21 207-783-5306 207-783-5307
## 3 207-255-3306 207-255-4815
## 4 207-941-3005 207-941-3012
## 5 207-872-7846 207-872-7858
## 6 207-324-1839 207-324-2763
## Email lat long address
## 2 mailvsome@va.gov <NA> <NA> 248 Room
## 21 Lewiston.MaineBVS@maine.gov 44.07552 -70.175044 35 Westminster Street
## 3 Machias.MaineBVS@maine.gov 44.718235 -67.453171 7 Court Street
## 4 Bangor.MaineBVS@maine.gov 44.813337 -68.741164 35 State Hospital Drive
## 5 Waterville.MaineBVS@maine.gov 44.569695 -69.627807 74 Drummond Avenue
## 6 Springvale.MaineBVS@maine.gov 43.455161 -70.789839 628 Main Street
## city state zip
## 2 Togus ME 04330
## 21 Lewiston ME 04240
## 3 Machias ME 04654
## 4 Bangor ME 04401
## 5 Waterville ME 04901
## 6 Springvale ME 04083One of the benefits of JSON is the ability to handle hierarchical data as we saw with the location information.
11.4 rtweet
Twitter provides an application programming interface (API) for making requests for data. The data are returned in a JSON format. The rtweet package shields us from working with the JSON data and by storing the data in a list object, and it has a convenient twListToDF() function to convert the object to a data frame. If you want to follow along in RStudio, you’ll need to perform a few steps to get the required authentication values to connect to Twitter.
- If you don’t already have one, create a twitter developer account at developer.twitter.com.
- After your account is activated and you are loged in, go to developer.twitter.com/en/apps.
- Click
Create New App - Fill in the required fields (use a placeholder URL if you don’t have a website)
- For Callback URLs, enter placeholder website address.
- Click yes to agree to the developer application and click
Create your Twitter application - Make a note of your app name.
- Click on the Keys and Tokens tab and make a note of your
Consumer KeyandConsumer Secret - Click
Create my access token(you only do this once) - Make a note of your
Access TokenandAccess Token Secret
We are going to first load all the libraries for the Twitter portion of this unit.
app <- "your_app_name_here"
consumer_key <- "your_consumer_key_here"
consumer_secret <- "your_consumer_secret_here"
access_token <- "your_access_token_here"
access_secret <- "your_access_secret_here"
my_token <- create_token(app = app,
consumer_key = consumer_key,
consumer_secret = consumer_secret,
access_token = access_token,
access_secret = access_secret)If you want to validate your token, if it works, it should return a token that differs from a blank token using get_token() (i.e., the results of identical should be FALSE).
## [1] FALSEThe first time you attempt to authenticate, you’ll be presented with a menu choice in the console – select option 1: Yes
We’ll use the search_tweets() function the last 1000 #Maine tweets. The Twitter API returns the tweets as a JSON stream which search_tweets converts to a dataframe. You can type str(mt) to get a concept of the structure. I’m not doing so in this code because there are a great many items in the returned tibble. Each column refers to the tweet or metadata about a specific tweet. Please note, that Twitter rate limits the results of a search so free accounts can’t return more than 18,000 results per 15 minutes. If you want more than that, you’ll have to use the retryonratelimit parameter in search_tweets
## # A tibble: 6 x 90
## user_id status_id created_at screen_name text source
## <chr> <chr> <dttm> <chr> <chr> <chr>
## 1 844000… 12576693… 2020-05-05 13:52:02 FishRiverA… Phew… Twitt…
## 2 250756… 12576683… 2020-05-05 13:48:02 Bijanjoon 5: .… Twitt…
## 3 250756… 12576674… 2020-05-05 13:44:15 Bijanjoon 4: B… Twitt…
## 4 250756… 12576648… 2020-05-05 13:34:02 Bijanjoon 2: I… Twitt…
## 5 208196… 12576667… 2020-05-05 13:41:29 DiannaCard Not … Twitt…
## 6 216332… 12576663… 2020-05-05 13:40:07 conpsweeney The … Hoots…
## # … with 84 more variables: display_text_width <dbl>, reply_to_status_id <chr>,
## # reply_to_user_id <chr>, reply_to_screen_name <chr>, is_quote <lgl>,
## # is_retweet <lgl>, favorite_count <int>, retweet_count <int>,
## # quote_count <int>, reply_count <int>, hashtags <list>, symbols <list>,
## # urls_url <list>, urls_t.co <list>, urls_expanded_url <list>,
## # media_url <list>, media_t.co <list>, media_expanded_url <list>,
## # media_type <list>, ext_media_url <list>, ext_media_t.co <list>,
## # ext_media_expanded_url <list>, ext_media_type <chr>,
## # mentions_user_id <list>, mentions_screen_name <list>, lang <chr>,
## # quoted_status_id <chr>, quoted_text <chr>, quoted_created_at <dttm>,
## # quoted_source <chr>, quoted_favorite_count <int>,
## # quoted_retweet_count <int>, quoted_user_id <chr>, quoted_screen_name <chr>,
## # quoted_name <chr>, quoted_followers_count <int>,
## # quoted_friends_count <int>, quoted_statuses_count <int>,
## # quoted_location <chr>, quoted_description <chr>, quoted_verified <lgl>,
## # retweet_status_id <chr>, retweet_text <chr>, retweet_created_at <dttm>,
## # retweet_source <chr>, retweet_favorite_count <int>,
## # retweet_retweet_count <int>, retweet_user_id <chr>,
## # retweet_screen_name <chr>, retweet_name <chr>,
## # retweet_followers_count <int>, retweet_friends_count <int>,
## # retweet_statuses_count <int>, retweet_location <chr>,
## # retweet_description <chr>, retweet_verified <lgl>, place_url <chr>,
## # place_name <chr>, place_full_name <chr>, place_type <chr>, country <chr>,
## # country_code <chr>, geo_coords <list>, coords_coords <list>,
## # bbox_coords <list>, status_url <chr>, name <chr>, location <chr>,
## # description <chr>, url <chr>, protected <lgl>, followers_count <int>,
## # friends_count <int>, listed_count <int>, statuses_count <int>,
## # favourites_count <int>, account_created_at <dttm>, verified <lgl>,
## # profile_url <chr>, profile_expanded_url <chr>, account_lang <lgl>,
## # profile_banner_url <chr>, profile_background_url <chr>,
## # profile_image_url <chr>The data frame contains the tweet along with 15 other metadata items including the screen_name, the retweet count, the platform/application (source) the tweet was created on, etc. Let’s look at a count of tweets by platform.
me_platform <- mt %>% group_by(source) %>%
summarize(n = n()) %>%
mutate(percent_of_tweets = n/sum(n)) %>%
arrange(desc(n))
me_platform %>% slice(1:10)## # A tibble: 10 x 3
## source n percent_of_tweets
## <chr> <int> <dbl>
## 1 Hootsuite Inc. 203 0.217
## 2 Twitter Web App 202 0.216
## 3 Twitter for iPhone 199 0.213
## 4 Twitter for Android 117 0.125
## 5 Instagram 67 0.0717
## 6 TweetDeck 38 0.0407
## 7 Twitter for iPad 22 0.0236
## 8 Buffer 15 0.0161
## 9 Twitter Web Client 11 0.0118
## 10 IFTTT 9 0.00964Next, we’ll take a look at the most active users.
mt %>%
group_by(screen_name) %>%
summarize(n = n()) %>%
mutate(percent_of_tweets = n/sum(n)) %>%
arrange(desc(n)) %>%
slice(1:10)## # A tibble: 10 x 3
## screen_name n percent_of_tweets
## <chr> <int> <dbl>
## 1 conpsweeney 114 0.122
## 2 jhhayman 63 0.0675
## 3 rick03907 30 0.0321
## 4 OnlineSentinel 16 0.0171
## 5 MailmanFarms 12 0.0128
## 6 PhilGondard 12 0.0128
## 7 1945rkn 10 0.0107
## 8 mainenewshound 10 0.0107
## 9 BasketIsOysters 8 0.00857
## 10 Hashhound1 8 0.00857Next, we’ll use tidytext with the same method described in the assigned reading to isolate the individual words. Note: all I did was copy/paste/modify the code from the article, we’ll explain text processing in future units.
reg <- "([^A-Za-z\\d#@']|'(?![A-Za-z\\d#@]))"
maine_words <- mt %>% select(status_id, text) %>%
filter(!str_detect(text, '^"')) %>%
mutate(text = str_replace_all(text, "https://t.co/[A-Za-z\\d]+|&", "")) %>%
unnest_tokens(word, text, token = "regex", pattern = reg) %>%
filter(!word %in% stop_words$word,
str_detect(word, "[a-z]"))
maine_words %>% group_by(word) %>% summarize(n = n()) %>% arrange(desc(n)) %>% top_n(20)## # A tibble: 20 x 2
## word n
## <chr> <int>
## 1 #maine 928
## 2 girl 188
## 3 maine 136
## 4 #murdermystery 104
## 5 glass 95
## 6 bridge 93
## 7 earlier 76
## 8 @pressherald 75
## 9 author 75
## 10 including 75
## 11 books 74
## 12 challenge 74
## 13 shown 74
## 14 @jhhayman 73
## 15 deft 73
## 16 fatal 73
## 17 obsession 73
## 18 plotting 73
## 19 prowess 73
## 20 sets 73Then we’ll do a sentiment analysis identical to the article. We’ll use the NRC lexicon from tidytext and join the sentiments to the words. The join will eliminate all words that don’t exist in both tables.
First, we create a data frame called nrc that is a table of words and their sentiments.
## # A tibble: 6 x 2
## word sentiment
## <chr> <chr>
## 1 abacus trust
## 2 abandon fear
## 3 abandon negative
## 4 abandon sadness
## 5 abandoned anger
## 6 abandoned fearThen we join nrc to maine_words and look at the sentiment counts.
maine_words_sentiments <- maine_words %>% inner_join(nrc, by = "word")
maine_words_sentiments %>% group_by(sentiment) %>% summarize(n = n()) %>% arrange(desc(n))## # A tibble: 10 x 2
## sentiment n
## <chr> <int>
## 1 positive 746
## 2 negative 513
## 3 trust 473
## 4 fear 392
## 5 anger 340
## 6 sadness 315
## 7 anticipation 298
## 8 joy 276
## 9 surprise 152
## 10 disgust 92Let’s take a look at some of the Maine tweets containing positive words. Note: the same tweets can also include other sentiment words, and a single sentiment word can have multiple sentiments.
pos_tw_ids <- maine_words_sentiments %>% filter(sentiment == "positive") %>% distinct(status_id)
mt %>% inner_join(pos_tw_ids, by = "status_id") %>% select(text) %>% slice(1:10)## # A tibble: 10 x 1
## text
## <chr>
## 1 "Phew, good thing Northern #Maine has been shut down the last month. Souther…
## 2 "5: ...though we may not always agree on the role of government, it is neces…
## 3 "4: But #Maine has survived this type of thing before, there's a toughness w…
## 4 "2: I'm a product of everything that is good and right about the state of #M…
## 5 "#Maine author @jhhayman has shown his deft plotting prowess in earlier book…
## 6 "#Maine author @jhhayman has shown his deft plotting prowess in earlier book…
## 7 "#Maine author @jhhayman has shown his deft plotting prowess in earlier book…
## 8 "#Maine author @jhhayman has shown his deft plotting prowess in earlier book…
## 9 "#Maine author @jhhayman has shown his deft plotting prowess in earlier book…
## 10 "#Maine author @jhhayman has shown his deft plotting prowess in earlier book…We can also look at ten of the tweets containing disgust words. We’ll include the disgust word in the output to illustrate that this simple form of sentiment analysis often doesn’t capture the actual sentiment of the tweet.
disg_tw_ids <- maine_words_sentiments %>% filter(sentiment == "disgust") %>% distinct(status_id, word)
mt %>% inner_join(disg_tw_ids, by = "status_id") %>% select(text, word) %>% slice(1:10)## # A tibble: 10 x 2
## text word
## <chr> <chr>
## 1 The Cutting tells about a #serialkiller dealing with #illegalorgantra… cutti…
## 2 The Cutting tells about a #serialkiller dealing with #illegalorgantra… cutti…
## 3 The Cutting tells about a #serialkiller dealing with #illegalorgantra… cutti…
## 4 The Cutting tells about a #serialkiller dealing with #illegalorgantra… cutti…
## 5 The Cutting tells about a #serialkiller dealing with #illegalorgantra… cutti…
## 6 The Cutting tells about a #serialkiller dealing with #illegalorgantra… cutti…
## 7 The Cutting tells about a #serialkiller dealing with #illegalorgantra… cutti…
## 8 The Cutting tells about a #serialkiller dealing with #illegalorgantra… cutti…
## 9 The Cutting tells about a #serialkiller dealing with #illegalorgantra… cutti…
## 10 The Cutting tells about a #serialkiller dealing with #illegalorgantra… cutti…Next, we’ll collect the #Vermont tweets and prepare the Vermont data to compare the platforms and sentiments between #Maine and #Vermont
vt <- search_tweets('#Vermont', n = num_tweets, include_rts = FALSE)
#show the platform
vt_platform <- vt %>% group_by(source) %>%
summarize(n = n()) %>%
mutate(percent_of_tweets = n / sum(n)) %>%
arrange(desc(n))
#extract the words and join to nrc sentiment words
vt_words <- vt %>% select(status_id, text) %>%
filter(!str_detect(text, '^"')) %>%
mutate(text = str_replace_all(text, "https://t.co/[A-Za-z\\d]+|&", "")) %>%
unnest_tokens(word, text, token = "regex", pattern = reg) %>%
filter(!word %in% stop_words$word,
str_detect(word, "[a-z]"))
vt_words_sentiments <- vt_words %>% inner_join(nrc, by = "word")Then we’ll combine the Vermont and Maine data after adding a “State” column.
me_platform$state <- "Maine"
vt_platform$state <- "Vermont"
maine_words_sentiments$state <- "Maine"
vt_words_sentiments$state <- "Vermont"
platform <- rbind(me_platform, vt_platform)
words_sentiments <- rbind(maine_words_sentiments, vt_words_sentiments)Now we can compare platforms. We’ll restrict to five platforms. I’ll use ggplot and create a bar chart. If you are interested in learning more about ggplot2, the Cookbook for R and the online documentation are good sources.
pf <- c("Twitter Web Client", "Twitter for iPhone", "Instagram", "Hootsuite Inc.", "Post Planner Inc.")
library(ggplot2)
pf_df <- platform %>% filter(source %in% pf)
ggplot(pf_df, aes(x = source, y = percent_of_tweets, fill = state)) +
geom_bar(stat = "identity", position = "dodge") +
xlab("Platform") +
ylab("Percent of tweets") +
theme(axis.text.x = element_text(angle = 90, hjust = 1))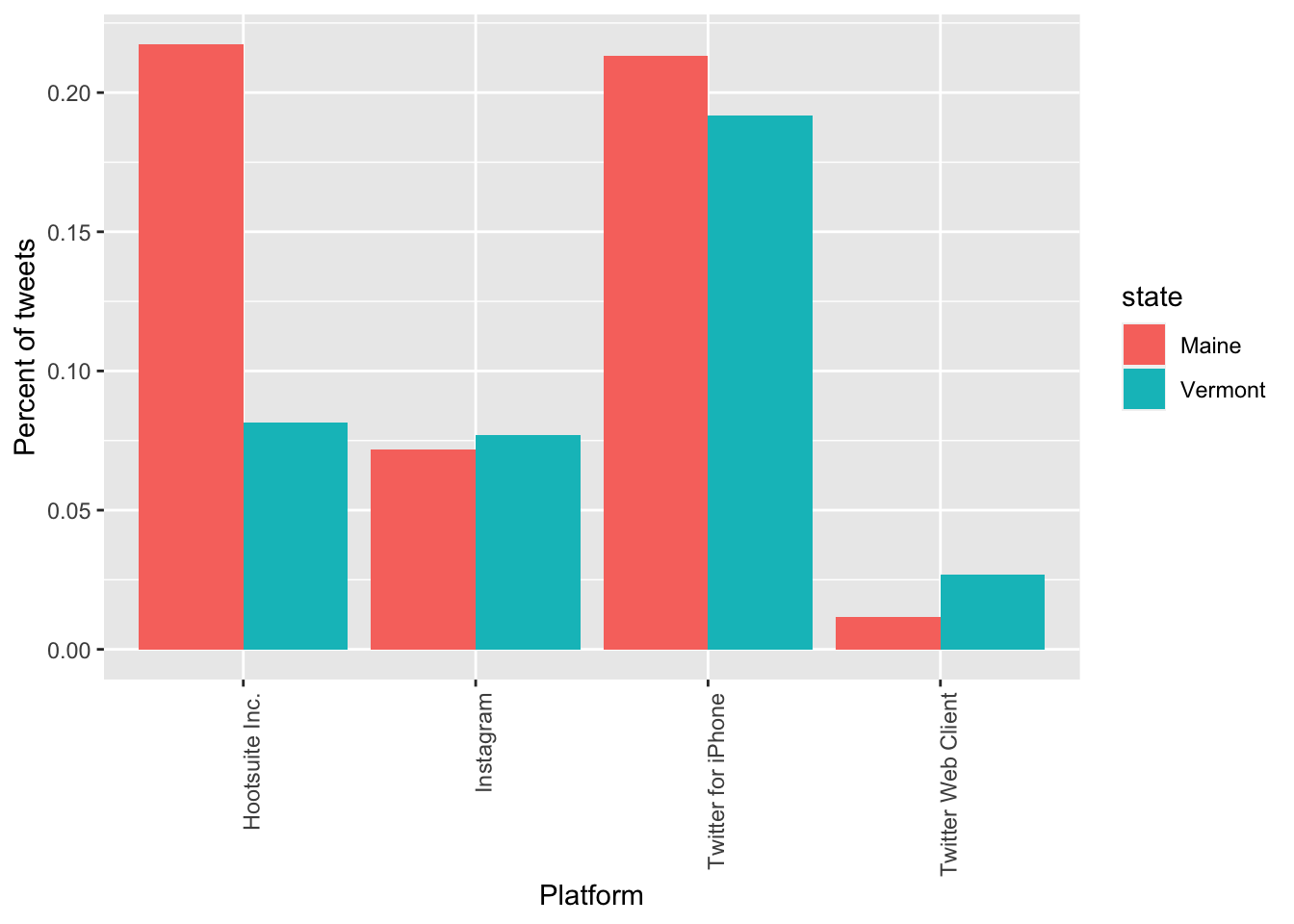
Finally, we can similarly compare sentiments.
sent_df <- words_sentiments %>%
group_by(state, sentiment) %>%
summarize(n = n()) %>%
mutate(frequency = n/sum(n))
ggplot(sent_df, aes(x = sentiment, y = frequency, fill = state)) +
geom_bar(stat = "identity", position = "dodge") +
xlab("Sentiment") +
ylab("Percent of tweets") +
theme(axis.text.x = element_text(angle = 90, hjust = 1))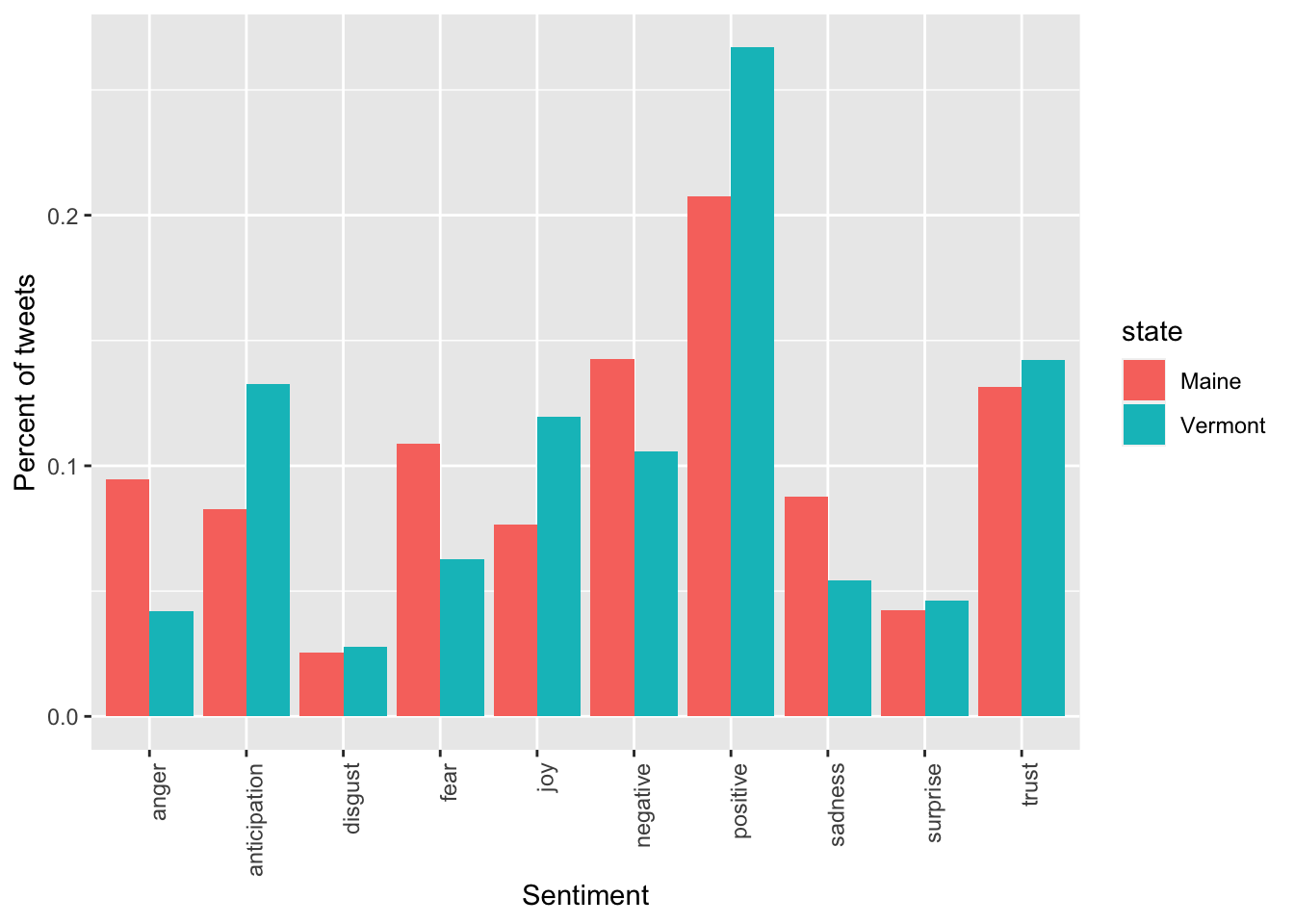
11.5 DataCamp Exercises
The DataCamp exercises for this unit start you with importing files from the web, then move into working with JSON. These are the last two DataCamp exercises for the course excluding the project.